Version 2024
This documentation specifies the format of datasets for the MonolixSuite starting in 2018. It details:
- General structure: structure of a dataset for population modeling
- Format rules: rules to format your experimental data, using the available column types
- Examples: examples of real datasets with typical features (continuous data, discrete data, time-to-event data, censored data, data with several types of measurements, …)
- Nonmem differences: key differences with the Nonmem format
©Lixoft
Dataset for population modeling
The considered datasets are dedicated to population modeling. The population approach describes phenomena observed in each of a set of individuals and the variability between individuals. The data is thus individual data, and is often longitudinal (over time). For each subject, the dataset contains measurements, dose regimen, covariates etc … i.e. all collected information.
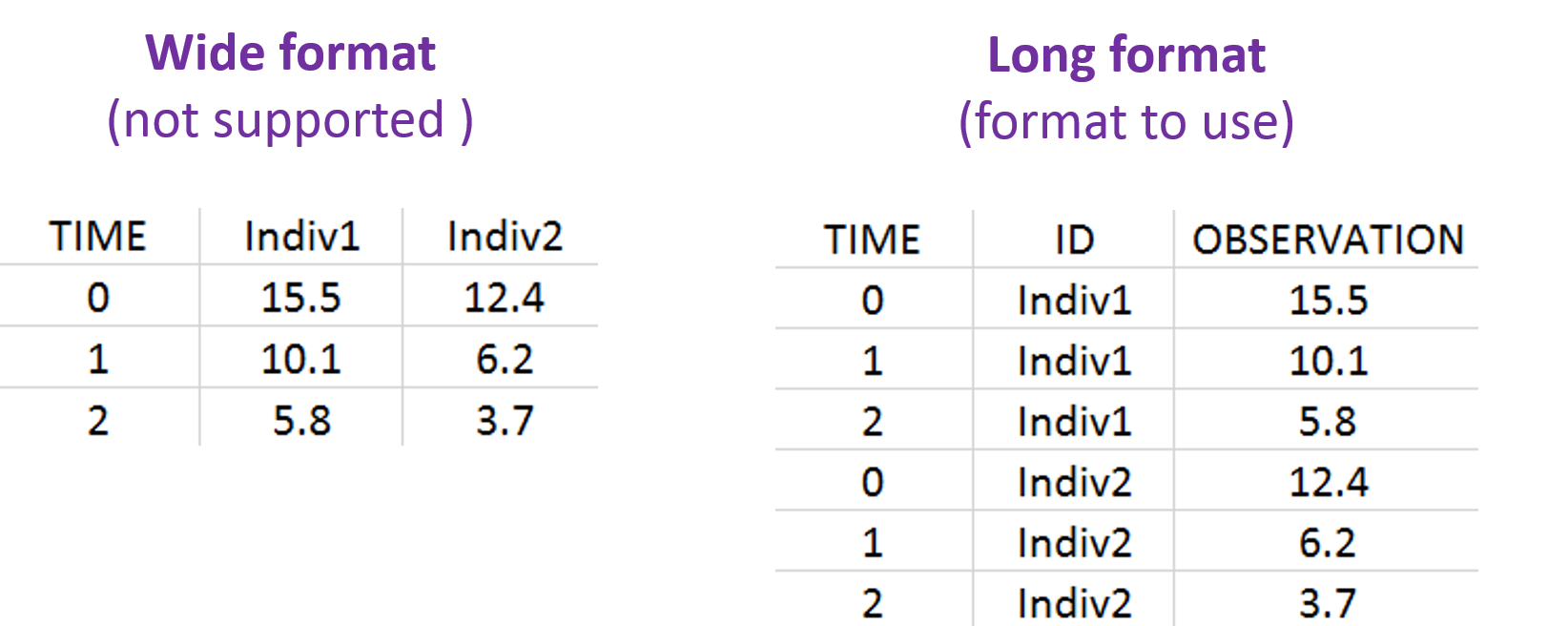
General format
The data must be in long format, i.e each row is one time point per subject. For each row, the individuals ID, observations, dose amount, covariates, etc are recorded in different columns. The column names in the dataset header can be set to anything, but the columns must be tagged using the available column types when defining the data in the applications of the MonolixSuite, such that the application knows how to interpret the data. The column types are very similar and compatible with the structure used by the Nonmem software.
File types: The file should be in text format with a file of .txt or .csv or .tsv. and the data must be separated by tab “\t”, comma “,”, semicolon “;” or a space ” “. A header line is required specifying the column names. Additionally, starting with version 2024, Excel files with extensions .xls or .xlsx and SAS files with extensions .sas2bdat, and .xpt are supported.