This data set has been originally published in:
The data arose from a clinical trial of 59 epileptics who were randomized to receive either the anti-epileptic drug progabide or a placebo, as an adjuvant to standard chemotherapy. The hope was that progabide would help to reduce the number of seizures experienced by patients. Patients attended four successive post-randomisation clinic visits, where the number of seizures that occurred over the previous 2 weeks was reported. At baseline, information on the age of the patient and the 8-week pre-randomisation seizure count was recorded.
Below is an extract of the data set:
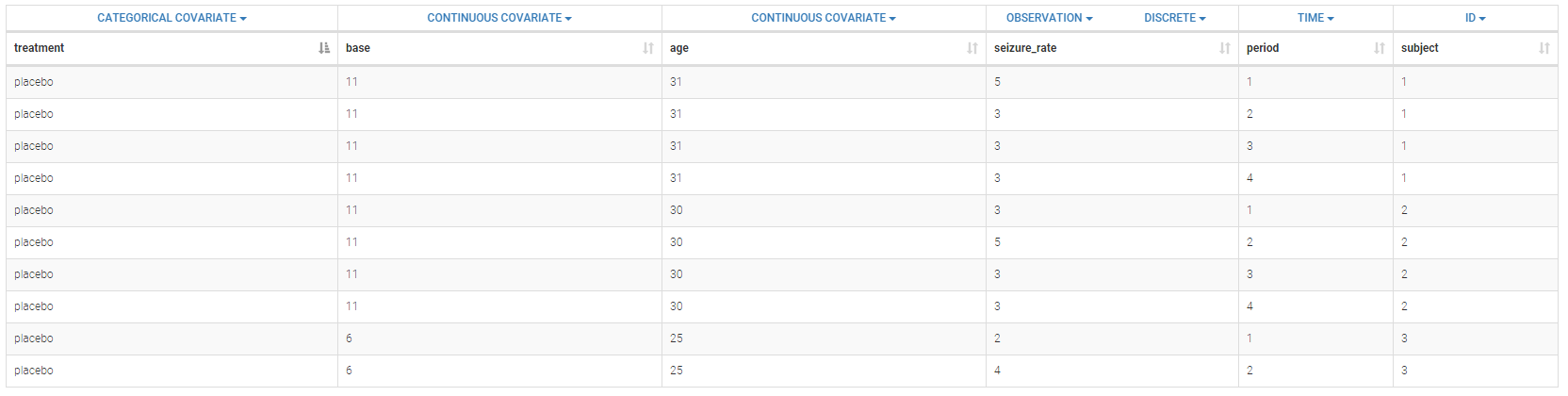 The columns have the following meaning:
The columns have the following meaning:
- treatment: factor with levels placebo progabide indicating whether the anti-epilepsy drug Progabide has been applied or not, column-type CATEGORICAL COVARIATE.
- base: number of epileptic attacks recorded during 8 week period prior to randomization, column-type CONTINUOUS COVARIATE.
- age: age of the patients, column-type CONTINUOUS COVARIATE.
- seizure_rate: number of epilepsy attacks patients have during the follow-up period, column-type OBSERVATION.
- period: measurement period, column-type TIME.
- subject: patient identification number, column-type ID.
Several points can be noticed:
- There are several seizure counts for each individual, thus the time allows to define to which period it is related.
- ID and TIME column are mandatory. Thus, if there is only one count measurement by individual, an additional column with TIME should be added (full of 0 for example).
- The covariates columns (treatment, base and age) are filled with the same value for each individual. Covariates must be constant within subjects (or subject-occasions when occasions are defined).
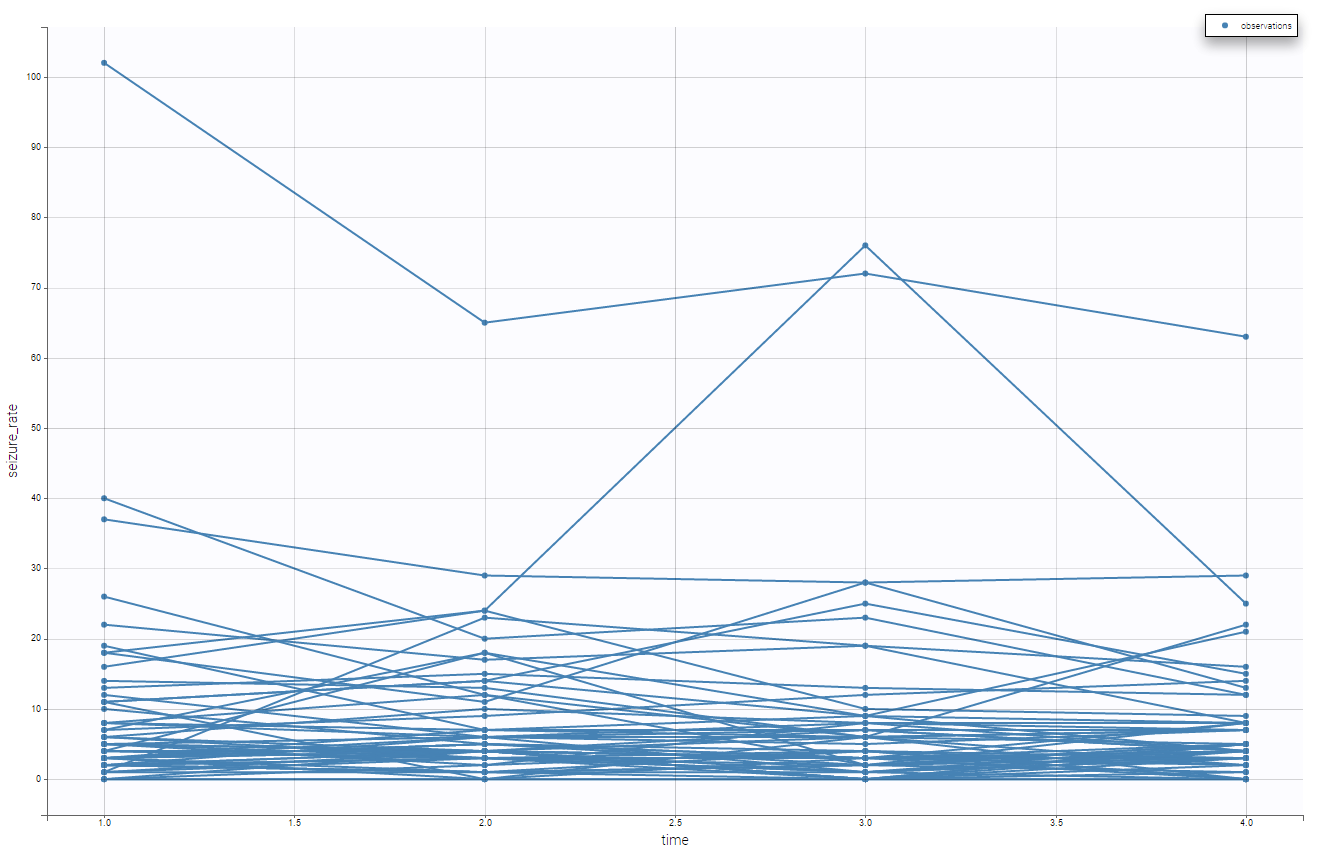
Moreover, we can split by the covariate treatment and thus see the impact of the treatment
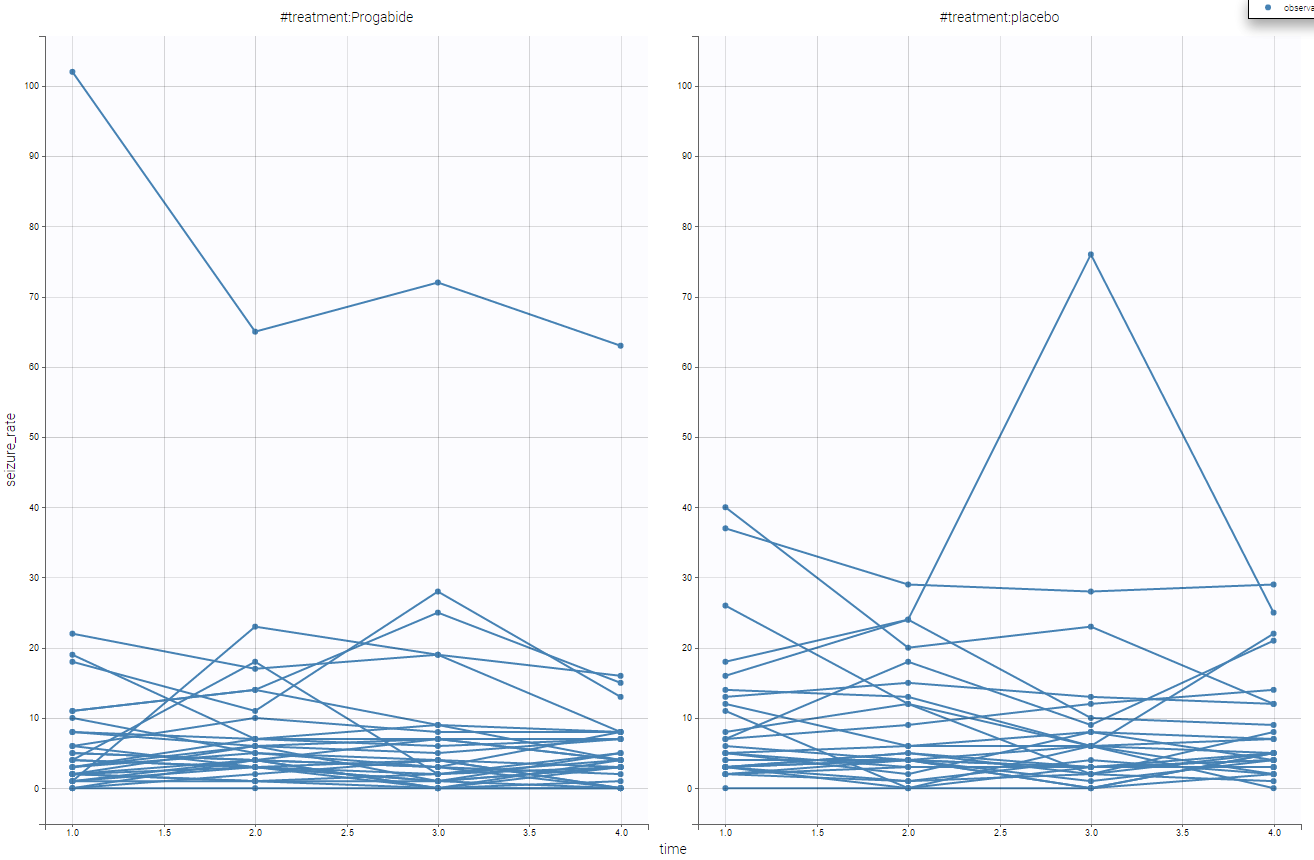
It seems the the subjects with the treatment have lower seizure rate. We can also display it grouped and not in a spaghetti display as in the following

Using that, we have a better understanding of the seizure_rate, and it seems that the treatment is effective.