REGRESSOR (formerly X): regression value
REGRESSOR columns define variables (possibly time-varying) that will be available for calculations in the structural model after regressor definition. Regressors can for instance be used to take into account time-varying covariates (example here), or tag the columns corresponding to individual PK parameters in a sequential PKPD modeling approach.
Allowed values in the REGRESSOR column are doubles and dot ‘.’ (to indicate missing values). For the first record (observation or dose line) of each subject (or subject-occasion if occasions are present), the regressor value cannot be missing (no dot ‘.’ allowed). For the following missing values, the interpolation will be done using the setting chosen in the GUI, which can be “Last Carried Forward” or “linear interpolation”. Regressor values on observation or dose lines are used the same way, as well as regressor values on lines with no observation and no dose.
- last carried forward: if we have defined in the dataset two times for each individual with (reg_A) at time (t_A) and (reg_B) at time (t_B)
- for (tle t_A), (reg(t)=reg_A) [first defined value is used]
- for (t_Ale t<t_B), (reg(t)=reg_A) [previous value is used]
- for (t>t_B), (reg(t)=reg_B) [previous value is used]
- linear interpolation: the interpolation is:
- for (tle t_A), (reg(t)=reg_A) [first defined value is used]
- for (t_Ale t<t_B), (reg(t)=reg_A+(t-t_A)frac{(reg_B-reg_A)}{(t_B-t_A)}) [linear interpolation is used]
- for (t>t_B), (reg(t)=reg_B) [previous value is used]
Several columns can be tagged as REGRESSOR. In that case, the mapping with the regressors defined in the model is done by name if possible, otherwise by order: the first column tagged as REGRESSOR in the data set is mapped to the first element in the model input list defined as regressor.
If within a subject (or subject-occasion if occasions are present) two events are defined at the same time on two different lines, the regressor value must be the same on both lines. The regressor value is used even if the dose or observation is ignored (for instance using the EVENT ID and IGNORED OBSERVATION columns).
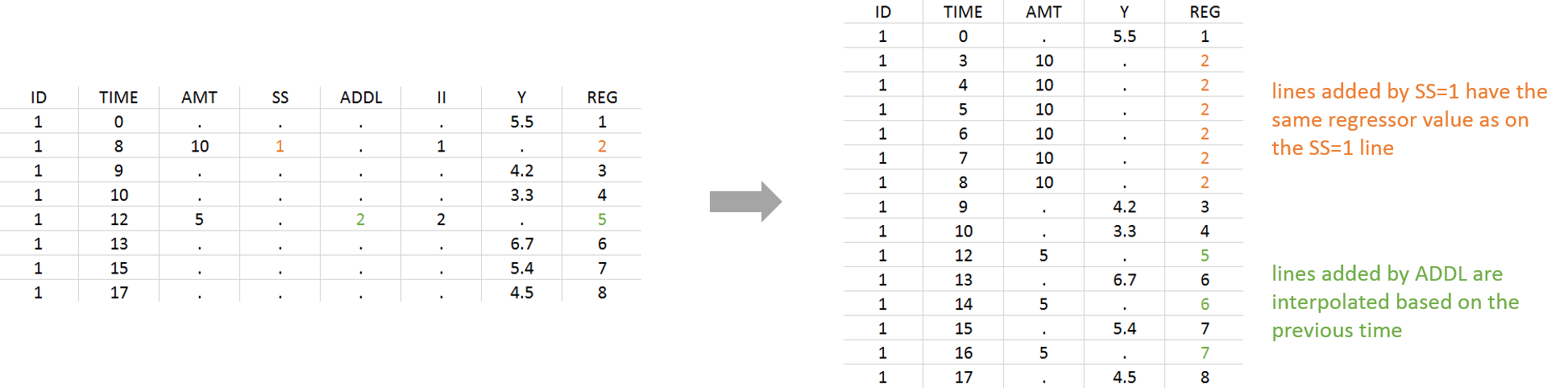
Lines added due to a STEADY-STATE column get the same regressor value as the line with the STEADY-STATE statement. Lines added due to an ADDITIONAL DOSES column get a dot ‘.’ and are then interpolated based on the previous values.
Examples:
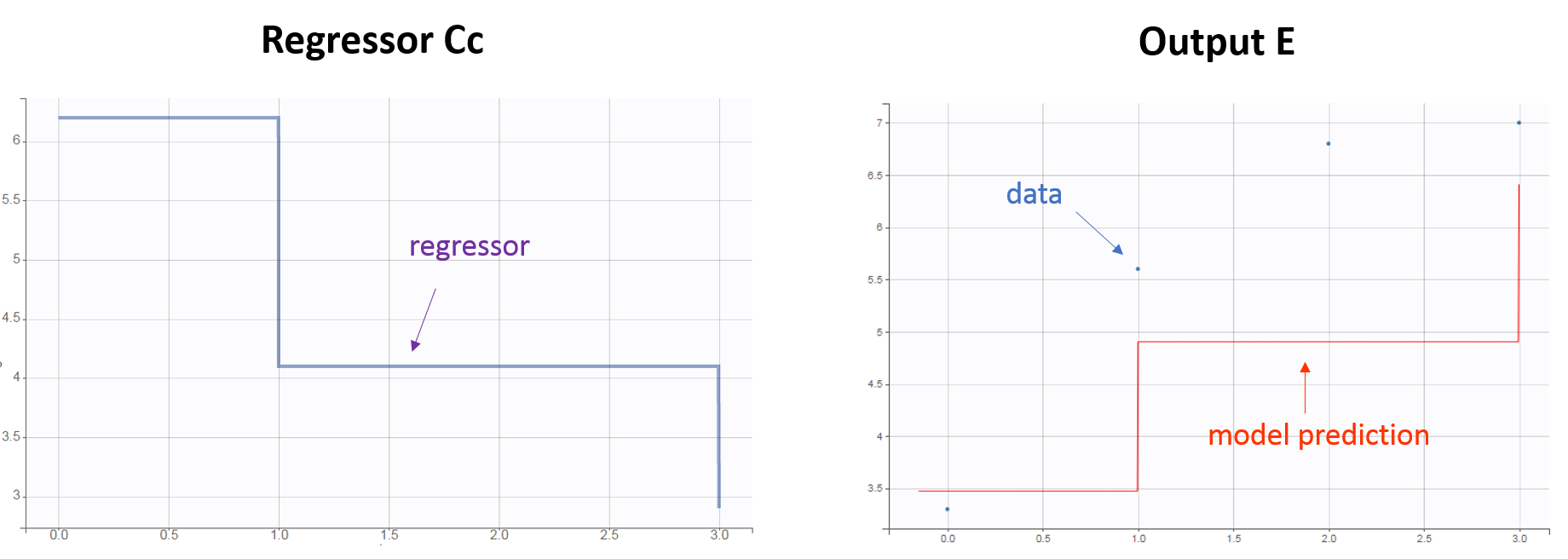
- Example with one regressor: the regressor corresponds to the drug concentration, which will be used in a direct effect PD model. With the following data set:
ID TIME Y REG
1 0 3.3 6.2
1 1 5.6 4.1
1 2 6.8 .
1 3 7.0 2.9
and the following model:
[LONGITUDINAL]
input = {E0, IC50 , Cc}
Cc = { use = regressor }
EQUATION:
E = E0 * (1 - Cc/(Cc+IC50))
OUTPUT:
output = {E}
The regressor variable Cc in the model will take the values defined in the REG column and be used to calculate the effect E. For time points not defined in the data set, interpolation will be done depending on the chosen Regressor Setting. If “Last Observation Carried Forward” is selected: during the time interval [0, 1[, the regressor value is that defined on time 0. Note that the column header and the model regressor variable name can differ.
- Example with two regressors: the regressors correspond to the individual PK parameters used to calculate the drug concentration, itself impacting the effect E. With the following data set:
ID TIME AMT Y V_mode k_mode 1 0 10 . 6.2 1.2 1 0 . 3.3 6.2 1.2 1 1 . 5.6 6.2 1.2 1 2 . 6.8 6.2 1.2 1 3 . 7.0 6.2 1.2
and the following model:
[LONGITUDINAL]
input = {E0, EC50 , V, k}
V = { use = regressor }
k = { use = regressor }
EQUATION:
Cc = pkmodel(V,k)
E = E0 * (1 - Cc/(Cc+EC50))
OUTPUT:
output = {E}
The first column tagged as REGRESSOR (V_mode) is mapped to the first regressor in the input list (V), and the REGRESSOR column of the data set (k_mode) is mapped to the second regressor of the model (k).

- Example with STEADY-STATE and ADDITIONAL DOSES:
Format restrictions:
- The regression-columns (i.e. columns with column-type REGRESSOR) shall contain either doubles or “.” (which will be interpolated).
- The first record for each subject (or subject-occasion) cannot be dot ‘.’ .
- When there are several lines with the same time, same id and same occasion, the value of the regressor column must be the same.