The required format for the data set in NONMEM and in the Monolix Suite is very similar. Usually only few changes (if any) are required to go from one format to the other one.
General formatting
- Column names: in the Monolix Suite column names are not restricted in length, and not restricted to uppercase format. Special characters such as spaces ” “, stars “*”, parentheses or brackets “(“, dashes “-“, slashes “/” are supported but are replaced by “_” in the interface and results.
- Header line: no need to start the header line with the “#” character in the Monolix Suite, the column headers line will be recognized automatically.
- Number of columns: there is no limitation of the number of columns in the Monolix Suite
Dose column-types
- STEADY STATE column: When a data set contains a column with column-type STEADY STATE (formerly SS), there must be a column with column-type INTERDOSE INTERVAL (formerly I)I. If STEADY STATE>0, then the value in the INTERDOSE INTERVAL column must be strictly positive. In case of steady-state, steady-state formulas are not used. Instead, additional doses (5 by default) are added before the STEADY STATE dose to reach steady-state.
- INFUSION RATE and INFUSION DURATION: in case of an infusion, in the Monolix Suite, it is possible to define either the rate (INFUSION RATE column-type, formerly RATE) or the duration (INFUSION DURATION column-type, formerly TINF). The rate and the duration are related to each other via the amount: TINF=RATE/AMT. Negative values in the RATE column-type result in a bolus, when used in combination with the iv macro (and models from the library with iv). When used in combination with the oral macro (and models from the library with oral0 or oral1), the RATE column is ignored if the value is negative and an error is triggered if the value is positive. If infusion duration is defined in the model (parameter or fixed value), the RATE column is not necessary (in opposition to NONMEM, where RATE=-1 and RATE=-2 are used).
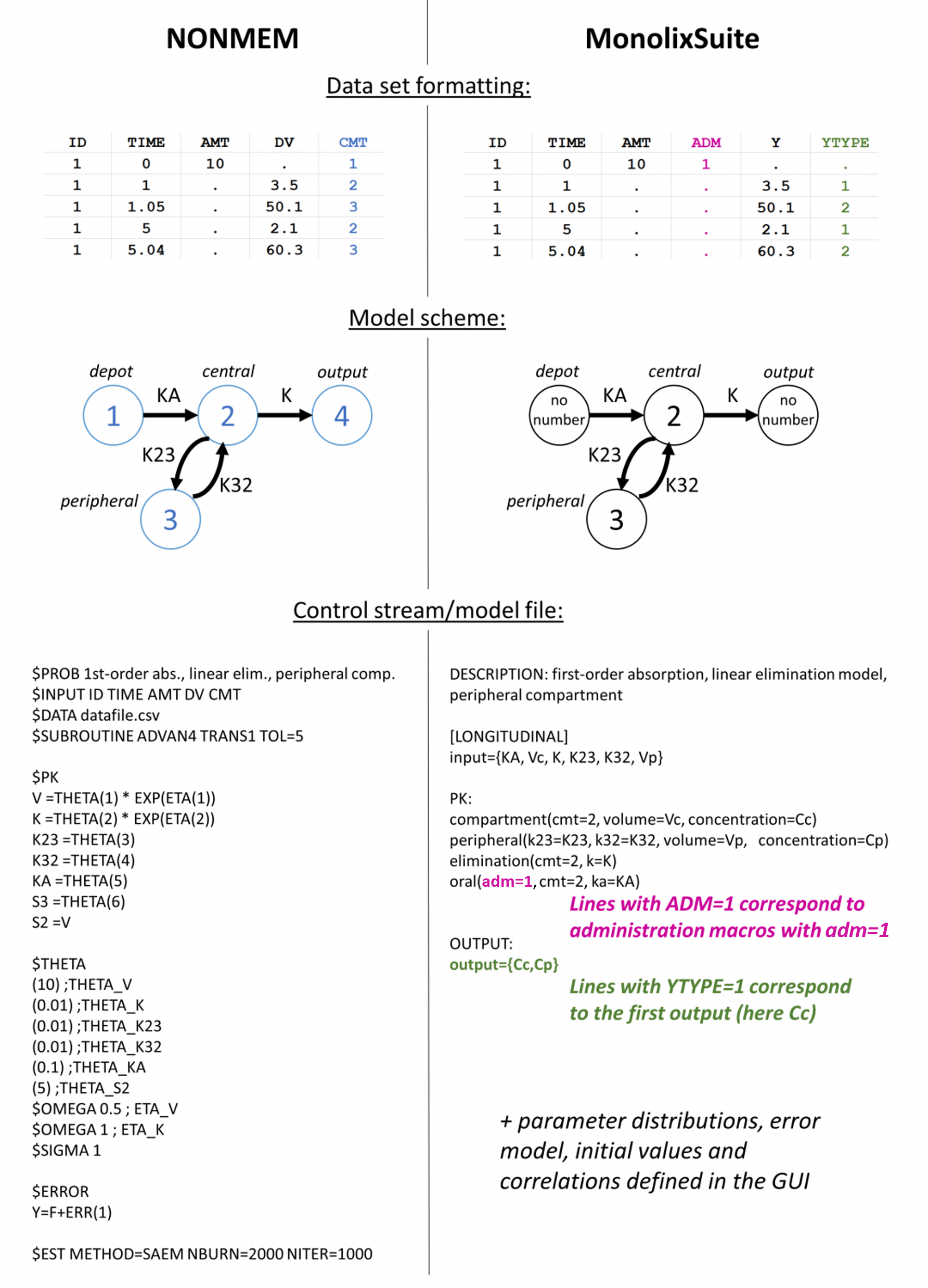
- CMT column: in NONMEM, for observation-lines, CMT specifies the compartment from which the predicted value of the observation is obtained. For dose-lines, CMT specifies the compartment into which the dose is introduced. In the MonolixSuite, the matching between the data (dose and observation lines) and the model (administrations and predictions) is done using identifiers, not based on compartment numbers. To assign a dose to a specific administration of the model (oral or iv macros for classical PK models, depot macro for more complex ODEs), the column ADMINISTRATION ID (formerly ADM) is used. The identifier in the ADMINISTRATION ID column should match the “adm=” field of the macro. To assign an observation to a prediction, the column OBSERVATION ID (formerly YTYPE) is used. Observation lines with OBSERVATION ID=1 will be assigned to the first output (output = {…} statement in the model file), lines with OBSERVATION ID=2 to the second output, etc. Note that the default values for the administration id in administration macros or in the pkmodel macro is adm=1. Similarly, in case of a single output, OBSERVATION ID=1 by default (while in NONMEM, the central compartment may have number 1 or 2). In the ADMINISTRATION ID column-type, negative values are not allowed. Turning off compartments should instead be defined in the model file.
Control and event columns-types
- EVID column-type: in the Monolix Suite, the EVENT ID (formerly EVID) column is not mandatory, since dose-events (EVENT ID=1) and response-events (EVENT ID=0) are automatically recognized. The Monolix Suite also recognizes EVENT ID=2 (“Other event”), EVID=3 (“Reset event”), and EVID=4 (which corresponds to a reset to initial values immediately followed by a dose). EVID=4 creates a new occasion for the individual. In NONMEM, EVID=2 is sometimes used to define a time point at which one would like to predict a concentration, without having an observation. In the Monolix Suite, no prediction will be outputted for that time in the output files.
- MDV column-type: the IGNORED OBSERVATION (MDV) column is not mandatory in the Monolix Suite. Dose-lines and observation-lines will be recognized automatically based on their contents. Yet the IGNORED OBSERVATION column can be useful to force a response-line to be ignored (IGNORED OBSERVATION=1). Several IGNORED OBSERVATION columns are allowed, in this case a synthetic IGNORED OBSERVATION value is computed. In the Monolix Suite, IGNORED OBSERVATION can in addition take the value IGNORED OBSERVATION=2, which is identical to IGNORED OBSERVATION = 1. Note that no prediction will be made at that time point in the output files. Simulx can be used to obtain predictions from a model at different time points.
Response column-types
- Censored data: in the Monolix Suite, censored data should be tagged in the data set using additional columns with CENSORING (formerly CENS) to mark censored observation, and if necessary LIMIT (give other interval boundary) column-types. The LOQ value is indicated in the OBSERVATION column. Censored data are then automatically taken into account in the likelihood in a rigorous statistical way. If only the CENSORING column is used, the method in the MonolisSuite is equivalent to the so-called M3 method. When both CENSORING and LIMIT are used, the method in equivalent to M4.
Subject identification columns-types
- ID column-type: in NONMEM all lines related to a single individual must be in one block, which is not the case in the Monolix Suite. If the ID column contains the following IDs: [1,1,1,2,2,1,1], NONMEM will consider that the dataset comprise three individuals with IDs 1 (with 3 observations), 2 (with 2 observations) and 1_1 (with 2 observations). In the Monolix Suite, two individuals are considered, with IDs 1 (with 5 observations) and 2 (with 2 observations).
Time column-types
- TIME column-type: values in the time column can be negative in the Monolix Suite.
Covariates and regression column-types
- Covariates: in the Monolix Suite, columns corresponding to continuous covariates must be set to the CONTINUOUS COVARIATE (formerly COV) column-type, and categorical covariates to the CATEGORICAL COVARIATE (formerly CAT) column-type.
- Regression variables: in the Monolix Suite, regression variables must be set to the REGRESSOR (formerly X) column-type. If several regression variables are used, their order must be the same in the dataset and in the “input” field of the model file. Interpolation between two regressor values is done using “last observation carried forward” in Monolix, while it is “next observation carried backward” in Nonmem. When converting a Nonmem dataset to Monolix format, the time-varying regressor columns must be shifted one cell up for each individual.

Unsupported column-types
- The PCMT, CONT, CALL, MRG_, RAW_, RPT_, L1, and L2 column-types are not supported in the MonolixSuite.